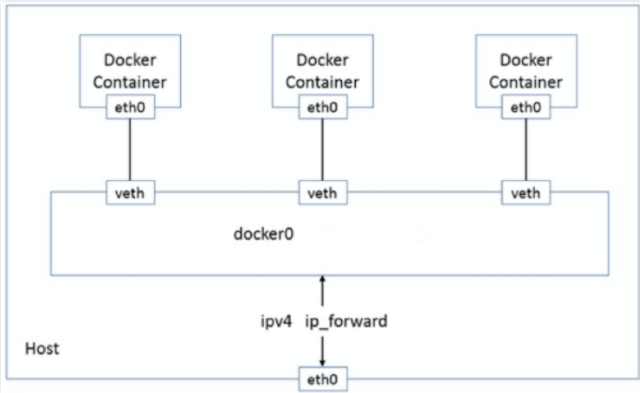
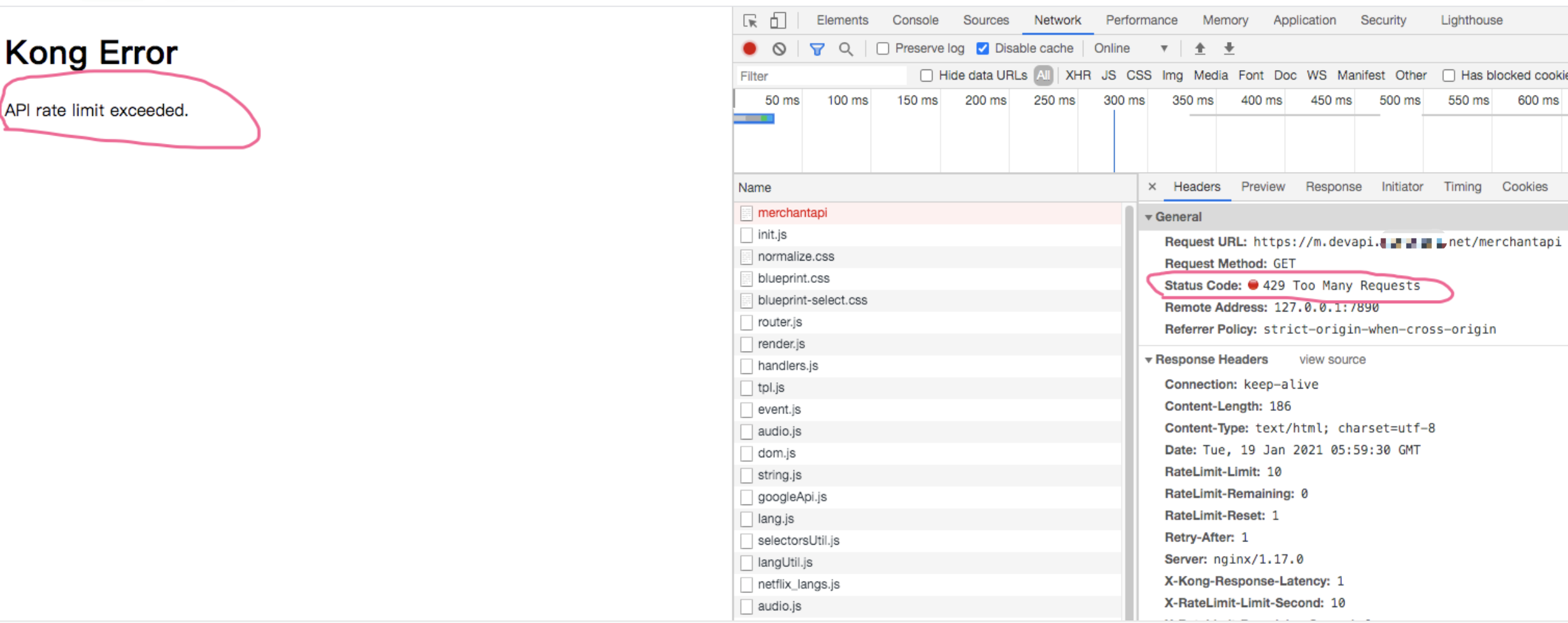
在 Linux 中,Cgroups 给用户暴露出来的操作接口是文件系统,即它以文件和目录的方式组织在操作系统的 /sys/fs/cgroup 路径下。,我可以用 mount 指令把它们展示出来,这条命令是:
1 2 3 4 5 6 7 8 9 10 11
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd) cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset) cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,freezer) cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory) cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio) cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpuacct,cpu) cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,hugetlb) cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,net_prio,net_cls) cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,pids) cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,devices) cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,perf_event)
[root@docker-dev overlay2]# ls 53f22fea6b813c35a5356493a840fb550fe75593174bc192446224a9bd0dddbd/diff anaconda-post.log bin dev etc home lib lib64 media mnt opt proc root run sbin srv sys tmp usr var
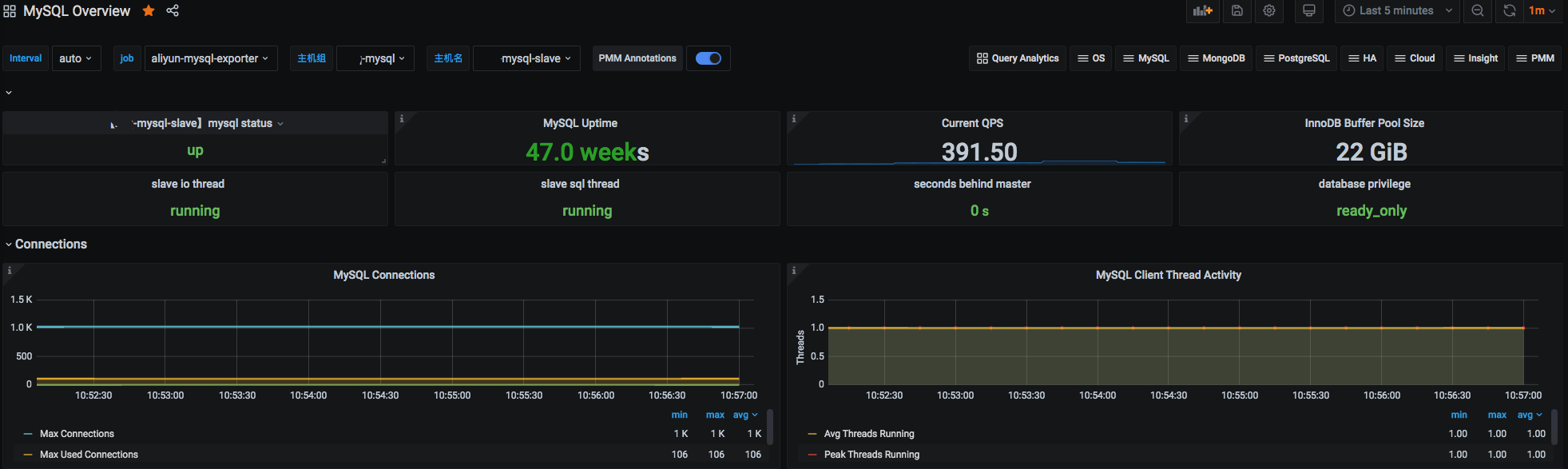
groups: - name: MySQLStatsAlert rules: - alert: MySQL is down expr: mysql_up == 0 for: 1m labels: severity: critical annotations: summary: "Instance {{ $labels.instance }} MySQL is down" description: "MySQL database is down. This requires immediate action!" - alert: open files high expr: mysql_global_status_innodb_num_open_files > (mysql_global_variables_open_files_limit) * 0.75 for: 1m labels: severity: warning annotations: summary: "Instance {{ $labels.instance }} open files high" description: "Open files is high. Please consider increasing open_files_limit." - alert: Read buffer size is bigger than max. allowed packet size expr: mysql_global_variables_read_buffer_size > mysql_global_variables_slave_max_allowed_packet for: 1m labels: severity: warning annotations: summary: "Instance {{ $labels.instance }} Read buffer size is bigger than max. allowed packet size" description: "Read buffer size (read_buffer_size) is bigger than max. allowed packet size (max_allowed_packet).This can break your replication." - alert: Sort buffer possibly missconfigured expr: mysql_global_variables_innodb_sort_buffer_size <256*1024 or mysql_global_variables_read_buffer_size > 4*1024*1024 for: 1m labels: severity: warning annotations: summary: "Instance {{ $labels.instance }} Sort buffer possibly missconfigured" description: "Sort buffer size is either too big or too small. A good value for sort_buffer_size is between 256k and 4M." - alert: Thread stack size is too small expr: mysql_global_variables_thread_stack <196608 for: 1m labels: severity: warning annotations: summary: "Instance {{ $labels.instance }} Thread stack size is too small" description: "Thread stack size is too small. This can cause problems when you use Stored Language constructs for example. A typical is 256k for thread_stack_size." - alert: Used more than 80% of max connections limited expr: mysql_global_status_max_used_connections > mysql_global_variables_max_connections * 0.8 for: 1m labels: severity: warning annotations: summary: "Instance {{ $labels.instance }} Used more than 80% of max connections limited" description: "Used more than 80% of max connections limited" - alert: InnoDB Force Recovery is enabled expr: mysql_global_variables_innodb_force_recovery != 0 for: 1m labels: severity: warning annotations: summary: "Instance {{ $labels.instance }} InnoDB Force Recovery is enabled" description: "InnoDB Force Recovery is enabled. This mode should be used for data recovery purposes only. It prohibits writing to the data." - alert: InnoDB Log File size is too small expr: mysql_global_variables_innodb_log_file_size < 16777216 for: 1m labels: severity: warning annotations: summary: "Instance {{ $labels.instance }} InnoDB Log File size is too small" description: "The InnoDB Log File size is possibly too small. Choosing a small InnoDB Log File size can have significant performance impacts." - alert: InnoDB Flush Log at Transaction Commit expr: mysql_global_variables_innodb_flush_log_at_trx_commit != 1 for: 1m labels: severity: warning annotations: summary: "Instance {{ $labels.instance }} InnoDB Flush Log at Transaction Commit" description: "InnoDB Flush Log at Transaction Commit is set to a values != 1. This can lead to a loss of commited transactions in case of a power failure." - alert: Table definition cache too small expr: mysql_global_status_open_table_definitions > mysql_global_variables_table_definition_cache for: 1m labels: severity: page annotations: summary: "Instance {{ $labels.instance }} Table definition cache too small" description: "Your Table Definition Cache is possibly too small. If it is much too small this can have significant performance impacts!" - alert: Table open cache too small expr: mysql_global_status_open_tables >mysql_global_variables_table_open_cache * 99/100 for: 1m labels: severity: page annotations: summary: "Instance {{ $labels.instance }} Table open cache too small" description: "Your Table Open Cache is possibly too small (old name Table Cache). If it is much too small this can have significant performance impacts!" - alert: Thread stack size is possibly too small expr: mysql_global_variables_thread_stack < 262144 for: 1m labels: severity: page annotations: summary: "Instance {{ $labels.instance }} Thread stack size is possibly too small" description: "Thread stack size is possibly too small. This can cause problems when you use Stored Language constructs for example. A typical is 256k for thread_stack_size." - alert: InnoDB Buffer Pool Instances is too small expr: mysql_global_variables_innodb_buffer_pool_instances == 1 for: 1m labels: severity: page annotations: summary: "Instance {{ $labels.instance }} InnoDB Buffer Pool Instances is too small" description: "If you are using MySQL 5.5 and higher you should use several InnoDB Buffer Pool Instances for performance reasons. Some rules are: InnoDB Buffer Pool Instance should be at least 1 Gbyte in size. InnoDB Buffer Pool Instances you can set equal to the number of cores of your machine." - alert: InnoDB Plugin is enabled expr: mysql_global_variables_ignore_builtin_innodb == 1 for: 1m labels: severity: page annotations: summary: "Instance {{ $labels.instance }} InnoDB Plugin is enabled" description: "InnoDB Plugin is enabled" - alert: Binary Log is disabled expr: mysql_global_variables_log_bin != 1 for: 1m labels: severity: warning annotations: summary: "Instance {{ $labels.instance }} Binary Log is disabled" description: "Binary Log is disabled. This prohibits you to do Point in Time Recovery (PiTR)." - alert: Binlog Cache size too small expr: mysql_global_variables_binlog_cache_size < 1048576 for: 1m labels: severity: page annotations: summary: "Instance {{ $labels.instance }} Binlog Cache size too small" description: "Binlog Cache size is possibly to small. A value of 1 Mbyte or higher is OK." - alert: Binlog Statement Cache size too small expr: mysql_global_variables_binlog_stmt_cache_size <1048576 and mysql_global_variables_binlog_stmt_cache_size > 0 for: 1m labels: severity: page annotations: summary: "Instance {{ $labels.instance }} Binlog Statement Cache size too small" description: "Binlog Statement Cache size is possibly to small. A value of 1 Mbyte or higher is typically OK." - alert: Binlog Transaction Cache size too small expr: mysql_global_variables_binlog_cache_size <1048576 for: 1m labels: severity: page annotations: summary: "Instance {{ $labels.instance }} Binlog Transaction Cache size too small" description: "Binlog Transaction Cache size is possibly to small. A value of 1 Mbyte or higher is typically OK." - alert: Sync Binlog is enabled expr: mysql_global_variables_sync_binlog == 1 for: 1m labels: severity: page annotations: summary: "Instance {{ $labels.instance }} Sync Binlog is enabled" description: "Sync Binlog is enabled. This leads to higher data security but on the cost of write performance." - alert: IO thread stopped expr: mysql_slave_status_slave_io_running != 1 for: 1m labels: severity: critical annotations: summary: "Instance {{ $labels.instance }} IO thread stopped" description: "IO thread has stopped. This is usually because it cannot connect to the Master any more." - alert: SQL thread stopped expr: mysql_slave_status_slave_sql_running == 0 for: 1m labels: severity: critical annotations: summary: "Instance {{ $labels.instance }} SQL thread stopped" description: "SQL thread has stopped. This is usually because it cannot apply a SQL statement received from the master." - alert: SQL thread stopped expr: mysql_slave_status_slave_sql_running != 1 for: 1m labels: severity: critical annotations: summary: "Instance {{ $labels.instance }} Sync Binlog is enabled" description: "SQL thread has stopped. This is usually because it cannot apply a SQL statement received from the master." - alert: Slave lagging behind Master expr: rate(mysql_slave_status_seconds_behind_master[1m]) >30 for: 1m labels: severity: warning annotations: summary: "Instance {{ $labels.instance }} Slave lagging behind Master" description: "Slave is lagging behind Master. Please check if Slave threads are running and if there are some performance issues!" - alert: Slave is NOT read only(Please ignore this warning indicator.) expr: mysql_global_variables_read_only != 0 for: 1m labels: severity: page annotations: summary: "Instance {{ $labels.instance }} Slave is NOT read only" description: "Slave is NOT set to read only. You can accidentally manipulate data on the slave and get inconsistencies..."
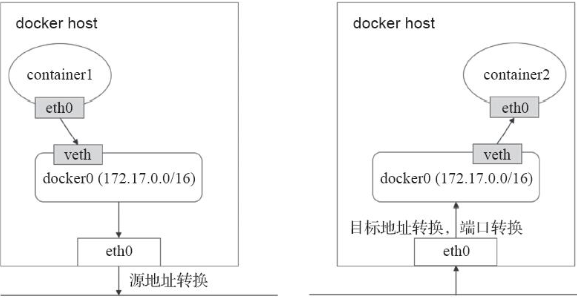
这好像通过 docker run –net –volumes-from 这样的命令就能实现嘛,比如:
1
$ docker run --net=B --volumes-from=B --name=A image-A ...
但是,你有没有考虑过,如果真这样做的话,容器 B 就必须比容器 A 先启动,这样一个 Pod 里的多个容器就不是对等关系,而是拓扑关系了。
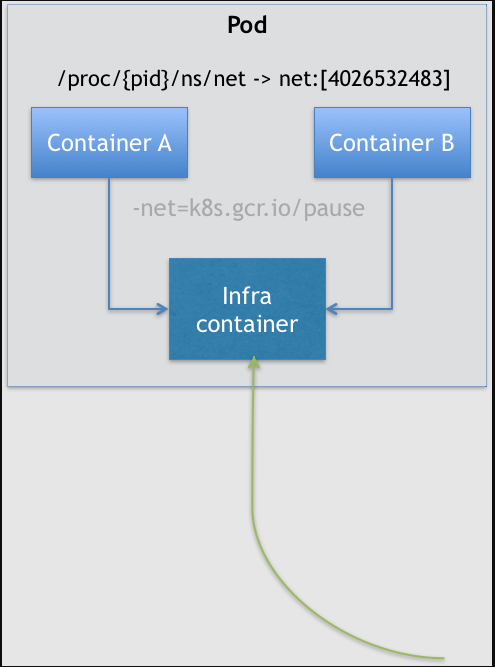
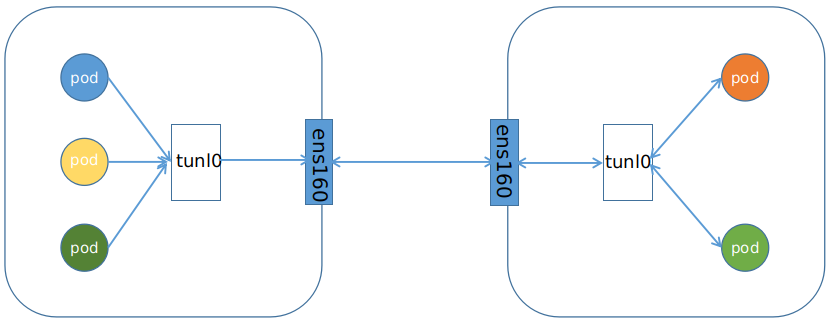
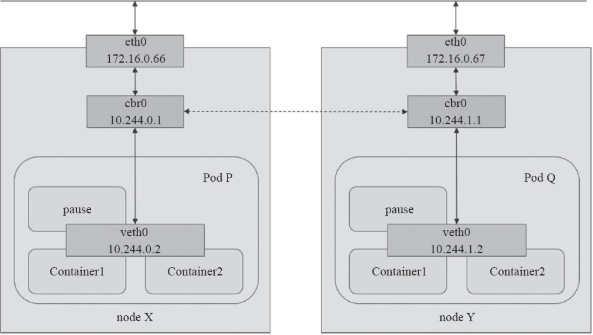
所以,在 Kubernetes 项目里,Pod 的实现需要使用一个中间容器,这个容器叫作 Infra 容器。在这个 Pod 中,Infra 容器永远都是第一个被创建的容器,而其他用户定义的容器,则通过 Join Network Namespace 的方式,与 Infra 容器关联在一起。这样的组织关系,可以用下面这样一个示意图来表达:
如上图所示,这个 Pod 里有两个用户容器 A 和 B,还有一个 Infra 容器。很容易理解,在 Kubernetes 项目里,Infra 容器一定要占用极少的资源,所以它使用的是一个非常特殊的镜像,叫作:k8s.gcr.io/pause。这个镜像是一个用汇编语言编写的、永远处于“暂停”状态的容器,解压后的大小也只有 100~200 KB 左右。
而在 Infra 容器“Hold 住”Network Namespace 后,用户容器就可以加入到 Infra 容器的 Network Namespace 当中了。所以,如果你查看这些容器在宿主机上的 Namespace 文件(这个 Namespace 文件的路径,我已经在前面的内容中介绍过),它们指向的值一定是完全一样的。
这也就意味着,对于 Pod 里的容器 A 和容器 B 来说:
它们可以直接使用 localhost 进行通信;
它们看到的网络设备跟 Infra 容器看到的完全一样;
一个 Pod 只有一个 IP 地址,也就是这个 Pod 的 Network Namespace 对应的 IP 地址;
当然,其他的所有网络资源,都是一个 Pod 一份,并且被该 Pod 中的所有容器共享;
Pod 的生命周期只跟 Infra 容器一致,而与容器 A 和 B 无关。
容器设计模式
Pod 这种“超亲密关系”容器的设计思想,实际上就是希望,当用户想在一个容器里跑多个功能并不相关的应用时,应该优先考虑它们是不是更应该被描述成一个 Pod 里的多个容器。
为了能够掌握这种思考方式,你就应该尽量尝试使用它来描述一些用单个容器难以解决的问题。
一个典型的例子就是容器的日志收集
比如,我现在有一个应用,需要不断地把日志文件输出到容器的 /var/log 目录中。
这时,我就可以把一个 Pod 里的 Volume 挂载到应用容器的 /var/log 目录上。
然后,我在这个 Pod 里同时运行一个日志收集客户端 容器,它也声明挂载同一个 Volume 到自己的 /var/log 目录上。
像这样,我们就用一种“组合”方式,解决了主容器和日志收集容器之间的耦合关系,而日志收集容器我们一般也称之为辅助容器.实际上,这个所谓的“组合”操作,正是容器设计模式里最常用的一种模式,它的名字叫:sidecar。顾名思义,sidecar 指的就是我们可以在一个 Pod 中,启动一个辅助容器,来完成一些独立于主进程(主容器)之外的工作。
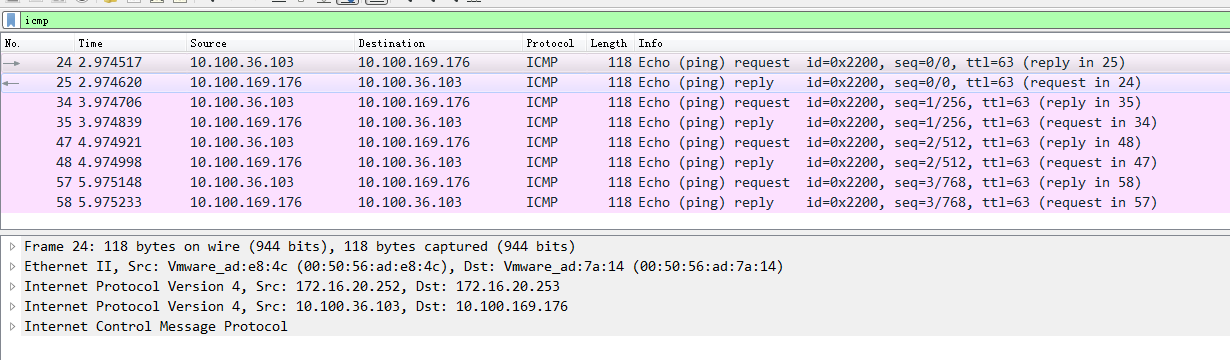
/ # ping 10.100.169.176 PING 10.100.169.176 (10.100.169.176): 56 data bytes 64 bytes from 10.100.169.176: seq=0 ttl=62 time=0.622 ms 64 bytes from 10.100.169.176: seq=1 ttl=62 time=0.552 ms 64 bytes from 10.100.169.176: seq=2 ttl=62 time=0.597 ms
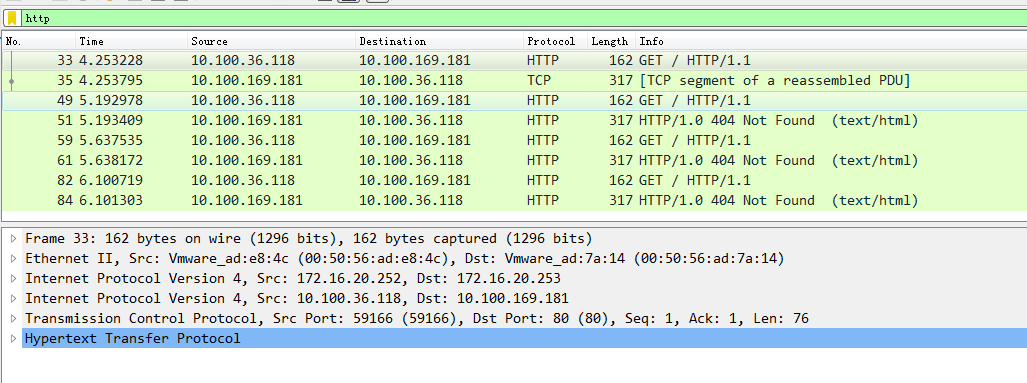
[root@k8s-master ~]$kubectl exec -it busybox-6hnvc -- sh / # curl http://10.96.166.242 sh: curl: not found / # wget -O - -q http://10.96.166.242 wget: server returned error: HTTP/1.0 404 Not Found / # wget -O - -q http://10.96.166.242 wget: server returned error: HTTP/1.0 404 Not Found
可以看到DaemonSet自动为这个Pod打上了很多容忍度,包括节点not-ready,unreachable,节点的磁盘,内存,pid的压力,以及哪怕节点被标记为unschedulable .就使得这些 Pod 可以忽略所有这些节点限制,继而保证每个节点上都会被调度一个 Pod。当然,如果这个节点有故障的话,这个 Pod 可能会启动失败,而 DaemonSet 则会始终尝试下去,直到 Pod 启动成功。
而在正常情况下,被标记了 unschedulable“污点”的 Node,是不会有任何 Pod 被调度上去的(effect: NoSchedule)
而通过这样一个 Toleration,调度器在调度这个 Pod 的时候,就会忽略当前节点上的“污点”,从而成功地将网络插件的 Agent 组件调度到这台机器上启动起来。
DaemonSet的滚动更新
通过命令查看daemonset的对象
1 2 3
[root@k8s-master daemonset]$kubectl get ds nginx -n kube-system NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE nginx 3 3 3 3 3 <none> 3h14m
[root@k8s-master daemonset]$kubectl set image ds nginx nginx=nginx:1.19.0 -n kube-system --record
观察升级过程
1 2 3 4 5 6 7 8 9
[root@k8s-master daemonset]$kubectl rollout status ds nginx -n kube-system Waiting for daemon set "nginx" rollout to finish: 1 out of 3 new pods have been updated... Waiting for daemon set "nginx" rollout to finish: 1 out of 3 new pods have been updated... Waiting for daemon set "nginx" rollout to finish: 1 out of 3 new pods have been updated... Waiting for daemon set "nginx" rollout to finish: 2 out of 3 new pods have been updated... Waiting for daemon set "nginx" rollout to finish: 2 out of 3 new pods have been updated... Waiting for daemon set "nginx" rollout to finish: 2 out of 3 new pods have been updated... Waiting for daemon set "nginx" rollout to finish: 2 of 3 updated pods are available... daemon set "nginx" successfully rolled out
在rollout history里就能看到滚动更新的记录:
1 2 3 4 5 6 7
[root@k8s-master daemonset]$kubectl rollout history daemonset nginx -n kube-system daemonset.apps/nginx REVISION CHANGE-CAUSE 3 kubectl set image ds/nginx nginx=nginx:latest --record=true --namespace=kube-system 4 <none> 5 kubectl set image ds/nginx nginx=nginx:latest --record=true --namespace=kube-system 6 kubectl set image ds nginx nginx=nginx:1.19.0 --namespace=kube-system --record=true
local 本地策略.计数器保存在Kong节点服务器本地内存缓冲区.并且计数器只对该节点有效.这意味着local策略有最好的性能表现.但是由于计数器存储在本地.所以限流的精度没有redis和cluster 准确.并且会影响Kong节点服务器弹性扩容(比如限流设置30r/s,Kong集群从2个节点扩容到4个节点.限流就从60r/s变成了120r/s.此时需要手动将限流设置从30r/s降低到15r/s)
Concurrency Level: 10 Time taken for tests: 1.180 seconds Complete requests: 100 #总共100个请求 Failed requests: 80 #失败了80个 (Connect: 0, Receive: 0, Length: 80, Exceptions: 0) Non-2xx responses: 80 Total transferred: 41888 bytes HTML transferred: 5720 bytes Requests per second: 84.71 [#/sec] (mean) Time per request: 118.044 [ms] (mean) Time per request: 11.804 [ms] (mean, across all concurrent requests) Transfer rate: 34.65 [Kbytes/sec] received ......
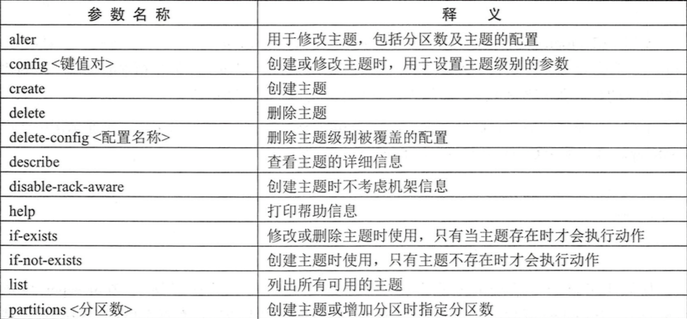
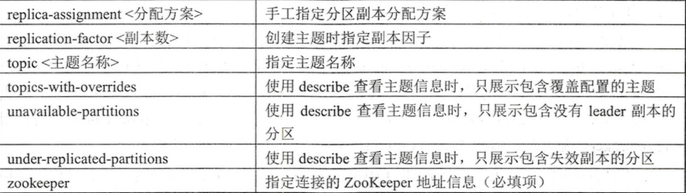
当一个主题被修改后,依然允许我们对其做一定的修改,比如修改分区个数,修改配置等.这个功能就是 kafka-topic.sh 脚本中的 alter 指令提供的.
以 topic-config 主题为例,该主题下只有一个分区.将分区修改为3:
1 2 3 4 5 6 7 8 9 10
[hadoop@bi-dev152 ~]$ /opt/kafka/bin/kafka-topics.sh --zookeeper localhost:2181 --alter --topic topic-config --partitions 3 WARNING: If partitions are increased for a topic that has a key, the partition logic or ordering of the messages will be affected Adding partitions succeeded!
hadoop@bi-dev152 ~]$ /opt/kafka/bin/kafka-topics.sh --zookeeper localhost:2181 --alter --topic topic-config --partitions 1 WARNING: If partitions are increased for a topic that has a key, the partition logic or ordering of the messages will be affected
Error while executing topic command : The number of partitions for a topic can only be increased
不支持减少分区主要是考虑到保障kafka的消息可靠性和顺序性,事务性问题.
如果修改一个不存在的主题分区,则会报错.添加 --if-exists 参数会忽略一些异常
1 2 3 4 5 6
hadoop@bi-dev152 ~]$ /opt/kafka/bin/kafka-topics.sh --zookeeper localhost:2181 --alter --topic topic-none-exist --partitions 3 Error while executing topic command : Topic topic-none-exist does not exist on ZK path localhost:2181
[hadoop@bi-dev152 ~]$ kafka-topics.sh --zookeeper localhost:2181 --alter --topic topic-config --config max.message.bytes=20000 WARNING: Altering topic configuration from this script has been deprecated and may be removed in future releases. Going forward, please use kafka-configs.sh for this functionality Updated config for topic "topic-config".
通过 alter 也可以删除创建主题时候的自定义配置.使用 --delete-config 参数.下面这个例子中删除了 max.message.bytes 配置.
1 2 3 4 5 6 7
[hadoop@bi-dev152 ~]$ kafka-topics.sh --zookeeper localhost:2181 --alter --topic topic-config --delete-config max.message.bytes WARNING: Altering topic configuration from this script has been deprecated and may be removed in future releases. Going forward, please use kafka-configs.sh for this functionality Updated config for topic "topic-config".
[hadoop@bi-dev152 ~]$ kafka-topics.sh --zookeeper localhost:2181 --delete --topic topic-demo1 Topic topic-demo1 is marked for deletion. Note: This will have no impact if delete.topic.enable is not set to true.
# Switch to enable topic deletion or not, default value is false delete.topic.enable=true
如果删除一个kafka的内部主题,那么会报错
1 2
[hadoop@bi-dev152 ~]$ kafka-topics.sh --zookeeper localhost:2181 --delete --topic __consumer_offsets Error while executing topic command : Topic __consumer_offsets is a kafka internal topic and is not allowed to be marked for deletion.
Save this to use as the --reassignment-json-file option during rollback Successfully started reassignment of partitions. [hadoop@bi-dev152 ~]$ [hadoop@bi-dev152 ~]$
Created preferred replica election path with {"version":1,"partitions":[{"topic":"topic-reassign","partition":0},{"topic":"topic-reassign","partition":1},{"topic":"topic-reassign","partition":2},{"topic":"topic-reassign","partition":3}]} Successfully started preferred replica election for partitions Set([topic-reassign,0], [topic-reassign,1], [topic-reassign,2], [topic-reassign,3])
Save this to use as the --reassignment-json-file option during rollback Warning: You must run Verify periodically, until the reassignment completes, to ensure the throttle is removed. You can also alter the throttle by rerunning the Execute command passing a new value. The throttle limit was set to 10 B/s Successfully started reassignment of partitions.
[hadoop@bi-dev152 ~]$ kafka-producer-perf-test.sh --topic topic-1 --num-records 1000000 --record-size 1024 --throughput -1 --producer-props bootstrap.servers=localhost:9092 acks=1 76666 records sent, 15333.2 records/sec (14.97 MB/sec), 1517.5 ms avg latency, 2061.0 max latency. 119400 records sent, 23880.0 records/sec (23.32 MB/sec), 1353.6 ms avg latency, 1631.0 max latency. 124560 records sent, 24912.0 records/sec (24.33 MB/sec), 1231.2 ms avg latency, 1375.0 max latency. 146520 records sent, 29304.0 records/sec (28.62 MB/sec), 1066.6 ms avg latency, 1146.0 max latency. 156795 records sent, 31359.0 records/sec (30.62 MB/sec), 972.3 ms avg latency, 1051.0 max latency. 133365 records sent, 26673.0 records/sec (26.05 MB/sec), 1141.1 ms avg latency, 1322.0 max latency. 159945 records sent, 31989.0 records/sec (31.24 MB/sec), 964.3 ms avg latency, 1178.0 max latency. 1000000 records sent, 26148.576210 records/sec (25.54 MB/sec), 1143.54 ms avg latency, 2061.00 ms max latency, 1114 ms 50th, 1654 ms 95th, 1869 ms 99th, 2036 ms 99.9th.
76666 records sent, 15333.2 records/sec (14.97 MB/sec), 1517.5 ms avg latency, 2061.0 max latency. 1114 ms 50th, 1654 ms 95th, 1869 ms 99th, 2036 ms 99.9th