kibana查询语法
介绍
在kibana6.3版本开始,kibana引入了Kibana Query Language(KQL)查询语法.并且从7.0版本开始已经是Kibana的默认查询语言.KQL包含脚本化字段查询和简易化的查询.
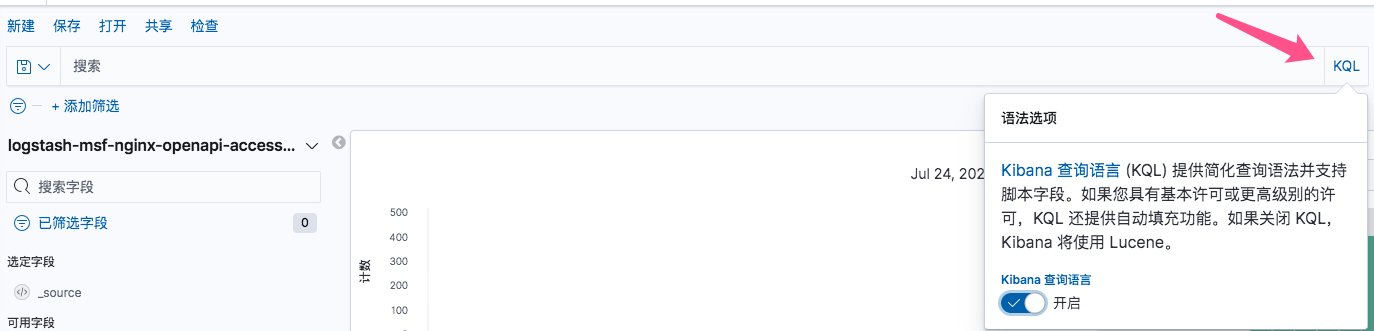
kibana支持以下两种查询语法:
Kibana query language (KQL)
Lucene query syntax (Lucene)
Discover
kibana的日志展示和搜索查询在discover界面中.在查询之前需要先指定:
- 索引名.指定要查询的索引,索引类似于关系型数据库(比如mysql)的库.
- 选择一个时间范围,或者时间点
discovery界面介绍
下面是一个搜索展示的页面
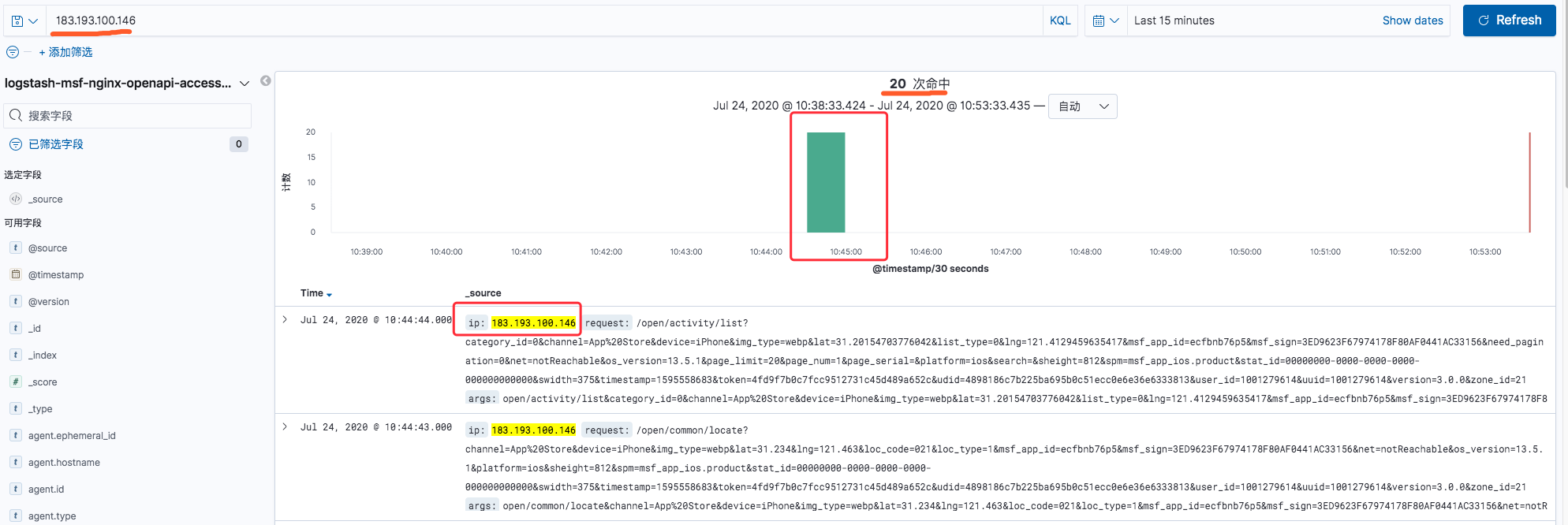
在界面中会统计查询结果条数,以及日志时间,在下面会展示查询结果的具体日志内容,以及高亮显示关键字.
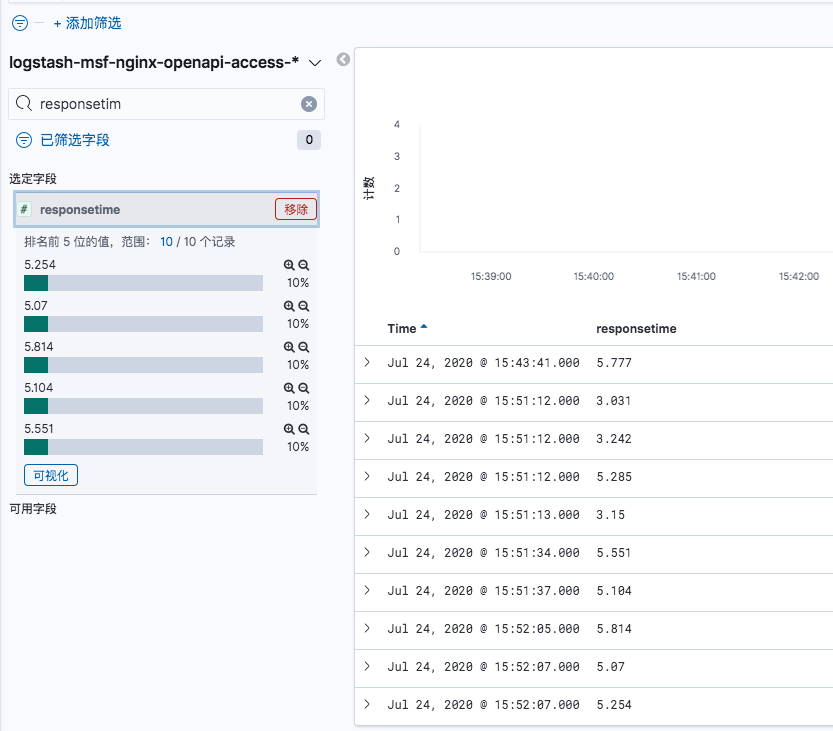
左侧栏中有字段值可以选择,例如在下面的搜索结果中,选择responsetime字段,可以详细看到字段的具体值,并且倒序排序..如果选定了字段后,在右侧就优先展示该字段的内容
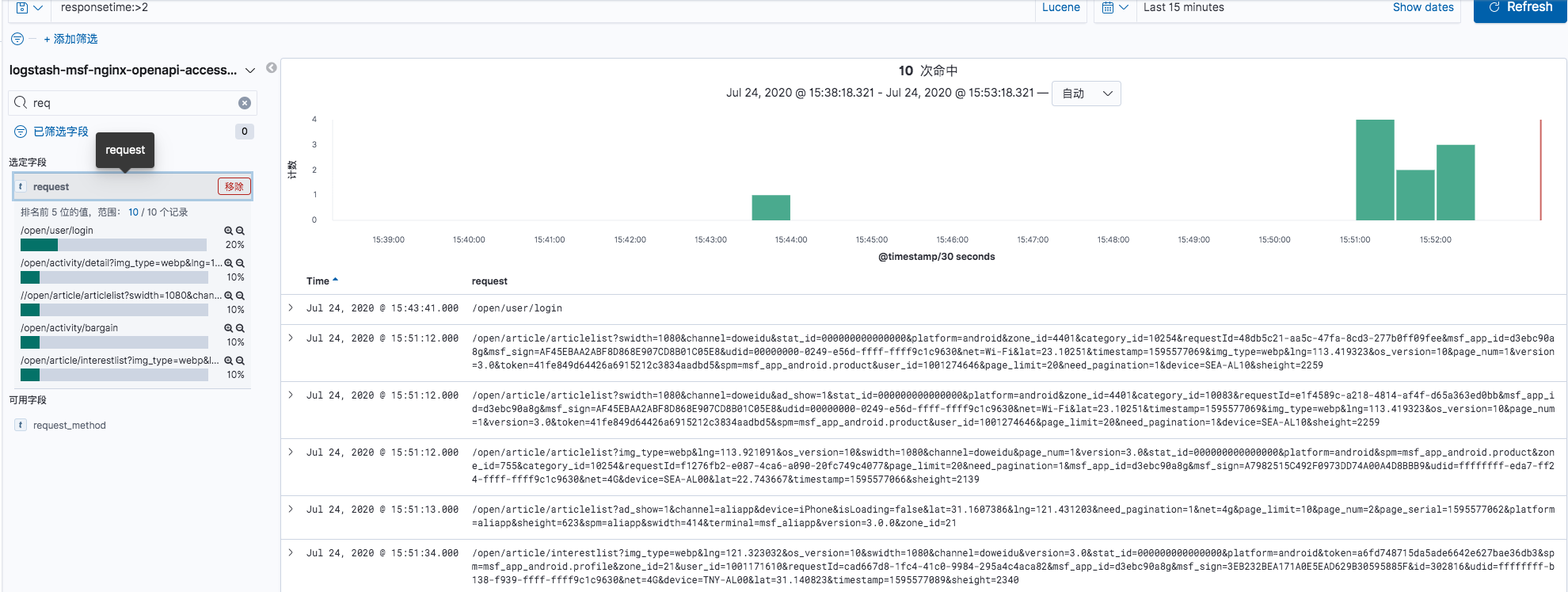
也可以在查询结果中,对其他字段进行排序,统计,例如在responsetime大于2的文档中,对request进行排序,
保存查询
对经常需要查询的字段或者语法,可以保存查询,方便下次再次查询,
查询语法
以下主要讲解KQL的查询语法.Lucene的查询语法大同小异,有区别之处会另行说明.
详细的语法可以参考elastic官网:kibana文档
全文搜索
在搜索栏直接输入要查询的关键词,如果关键词包含空格,特殊字符,中文等,使用双引号起来作为一个短语进行搜索.
当数据量较大时,全文搜索比较缓慢,因为ES需要去日志的所有字段中依次查找关键字
注意
当需要搜索msf-api1这个关键词时,需要将这个短语用双引号括起来,否则会搜索任何满足msf关键词的数据
字段匹配
全文搜索比较缓慢,因为需要从所有字段中查找匹配的关键字,这个时候指定字段名,查询速度就会非常快,.
语法格式: 字段名:值
查询状态为200的Nginx日志: status:200
查询主机为msf-api1的所有日志: hostname: “msf-api1”
逻辑操作
操作符: AND ,OR
例如.我要寻找request请求URL字段中包含关键字632303f301bebf55724ed28eaba6ec6477cb5670,同时来自msf-api1的服务器,并且status状态为200的日志
1 | request:632303f301bebf55724ed28eaba6ec6477cb5670 AND status:200 AND hostname:"msf-api1" |
在KQL查询语法中,AND操作符不能省略,否则会报错,但是在Lucene中可以省略
默认AND操作符的优先级要高于OR,例如response:200 and extension:php or extension:css会匹配所有response为200并且extension为php,或者extension为CSS但是response为所有的文档.
单字段逻辑查询
逻辑操作符还有更方便的做法,可以针对一个单一的字段指定多个值.例如
status:(200 or 499) 表示查询status为200或者499的文档
tags:(success and info and security) 表示同时具有以上tags的文档
分组查询
像数学运算一下,可以使用括号来指定优先级,
比如response:200 and (extension:php or extension:css)会匹配所有response为200并且extension是php或者css的查询结果
not操作符
使用not前缀,表示一个否定的查询.
例如: not response:200 会匹配所有response不等于200的文档
not还可以结合分组查询使用
response:200 and not (extension:php or extension:css)匹配所有response为200,并且extesnion不等于php或者css的文档
KQL范围查询
使用运算符号>,>=,<,<=等可以进行范围查询.
在使用范围查询的时候可以省略字段后的冒号,比如查询Nginx中的cost值大于1秒的文档.
responsetime>1 (在我的nginx日志中定义responsetime字段表示cost值)
IP地址也可以使用运算符查询,例如查询大于10.111.30.34的主机IP:
host.ip>10.111.30.34
Lucene的范围查询:
格式: [START_VALUE TO END_VALUE]
例如查询Nginx400-499的状态:
status: [400 TO 499]
例如查询10个以上的计数:
count:[10 TO *]
2012年之前的日期
date:{* TO 2012-01-01} 或者 date:[* TO 2012-01-01]
查询IP地址范围:host_ip:[10.111.10.34 to 10.111.10.40]
中括号和大括号可以混合使用,例如下面例子中表示从1-4的数字,(不包括5)
count:[1 TO 5}
注:
[ ]表示端点数值包含在范围内,{ }表示端点数值不包含在范围内
Lucene范围运算符
1 | age:>10 |
例如:要寻找cost值在1-2秒之间的文档,可以写成
1 | #1.responsetime:(>=1 AND <=2) |
Lucene 加减查询
Lucene的+和-号有特殊涵义:
+: 表示匹配该项
-:表示不匹配该项.和NOT作用类似
例如下面这个例子匹配responsetime大于2,但是status不为200的文档
+responsetime:>2 -status:200
在下面的例子中表示fox关键字必须匹配,news关键字必须排除,quick和brown则是可选项,有就显示,没有也无所谓
quick brown +fox -news
通配符查询
KQL也支持通配符字段,使用字段:*表示查询所有存在该字段的文档.在下面的例子中表示查询所有msf-api开头的主机
hostname:"msf-api*"
通配符不仅可以应用在值上,在字段中也可以使用通配符,比如有machine.os和machine.os.keyword这2个字段.如果想查找这两个字段都包含一个windows 10的值,可以使用machine.os*:windows 10
lucene正则
lucene支持部分正则语法.
?表示匹配一个单一的字符
*表示匹配0到无限个字符
~波浪线表示模糊匹配..例如quikc~ brwn~ fok~
官方建议最好不要使用正则查询,因为会消耗大量内存并且查询速度较慢
正则表达式可以使用斜杠包括起来.例如:
name:/joh?n(ath[oa]n)/
特殊字符转换
如果查询的字段或者内容中包含以下特殊字符,需要转义
1 | + - = && || > < ! ( ) { } [ ] ^ " ~ * ? : \ / |

