kibana索引及索引冷热分离管理
介绍
本篇文档简单介绍一下kibana的索引管理.主要包括:
- 索引模板
- 索引模式
- 索引生命周期
- 索引冷热分离管理
- 索引模板配置
索引模板
ES自带一个默认的logstash-*的索引模板,es内部维护了template,template定义好了mapping,只要index的名称被template匹配到,那么该index的mapping就按照template中定义的mapping自动创建。而且template中定义了index的shard分片数量、replica副本数量等等属性。
所以我们每次新建一个索引的时候,不需要手动创建mapping映射,也不需要手动设置副本和分片数量.
在Kibana的图形化界面中可以看到ES默认的索引模板
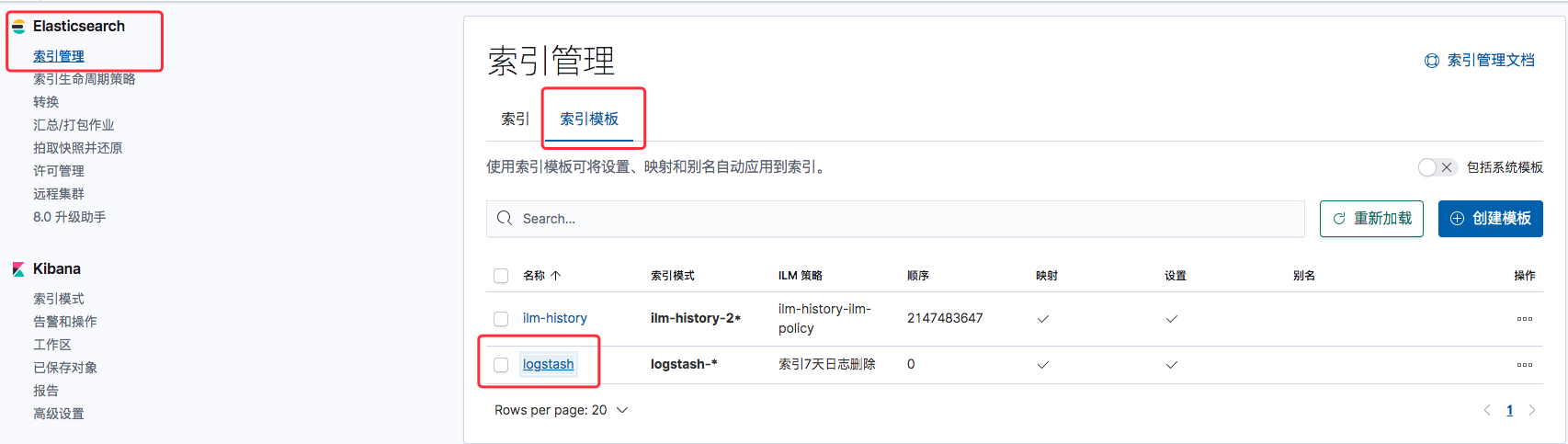
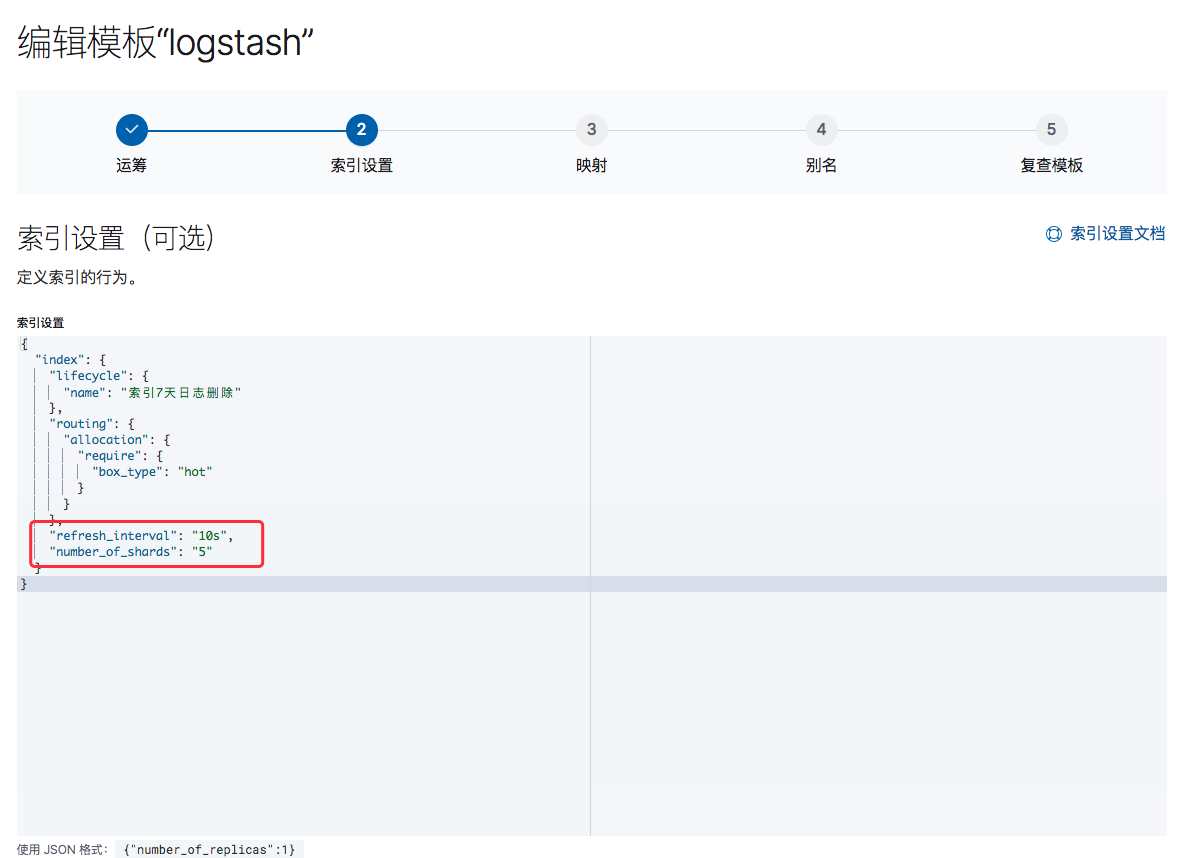
点击进入logstash索引模板,还能对模板进行编辑.比如设置以下重要2个参数:
refresh_interval —-索引刷新间隔,一般在5-10秒范围内,周期可以设置长一点,有助于提高ES性能,减少不必要的刷新
number_of_shards—–索引分片数量,在ES7版本中默认为1,在以前的版本默认为5.一般情况下设置为等同于ES data节点的数量
number_of_replicas—-默认副本数量为1,如果有特殊需要,可以在下方设置.
由于ES默认索引模板的存在,所以logstash在向ES传输数据的时候,索引最好是以logstash-开头.例如:
1 | output { |
索引模式
当一个新建的索引传输到ES时,需要将这个索引关联到刚才提到的索引模板中.比如下面的logstash-msf-mysql-slow-2020.02.28的索引

在Kibana的索引模式界面中,创建一个索引模式
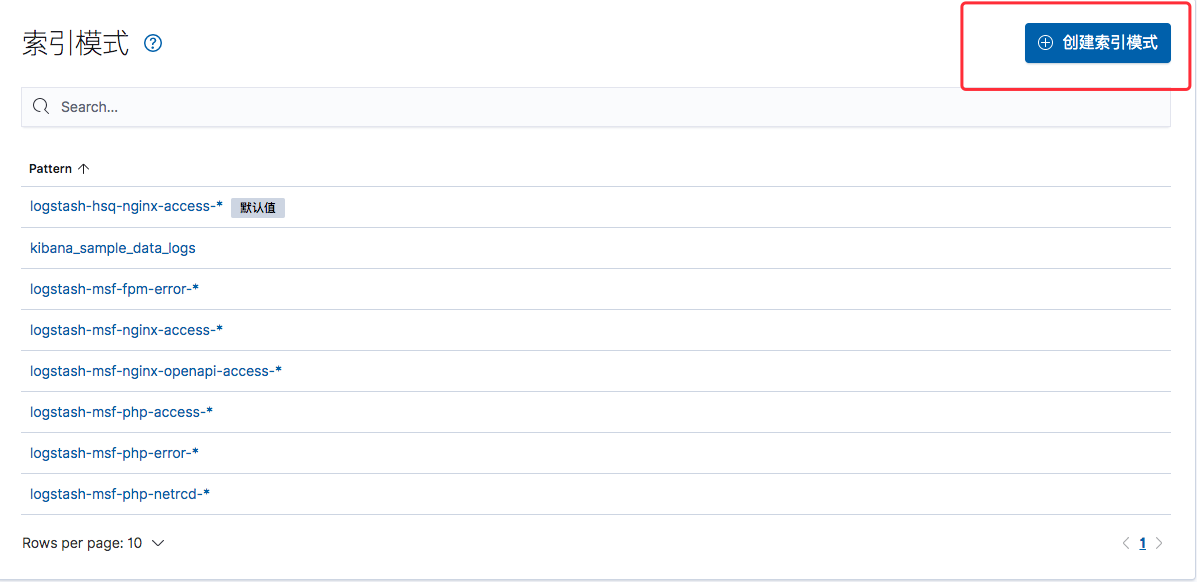
由于每天创建一个索引,所以定义一个索引前缀,使用通配符匹配后面的日期
logstash-msf-mysql-slow-*
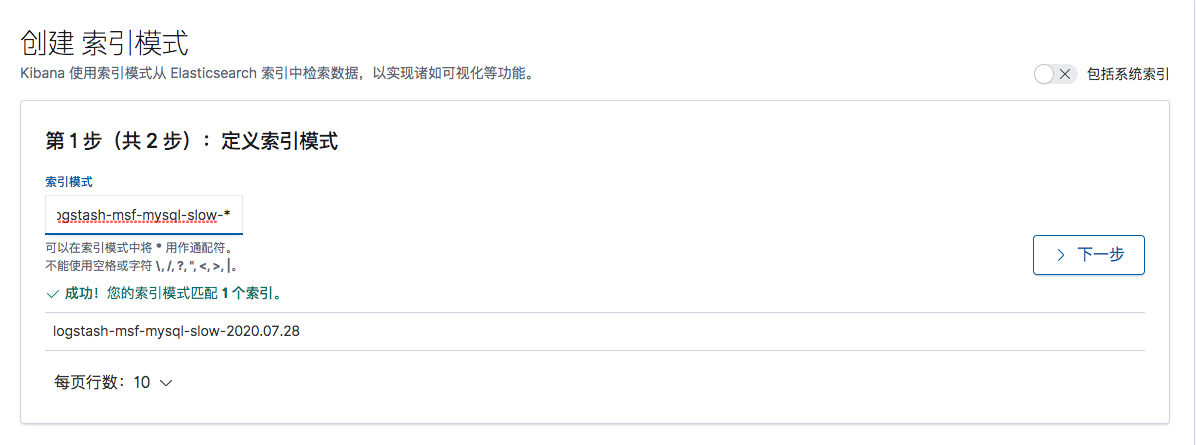
默认使用日期来筛选字段
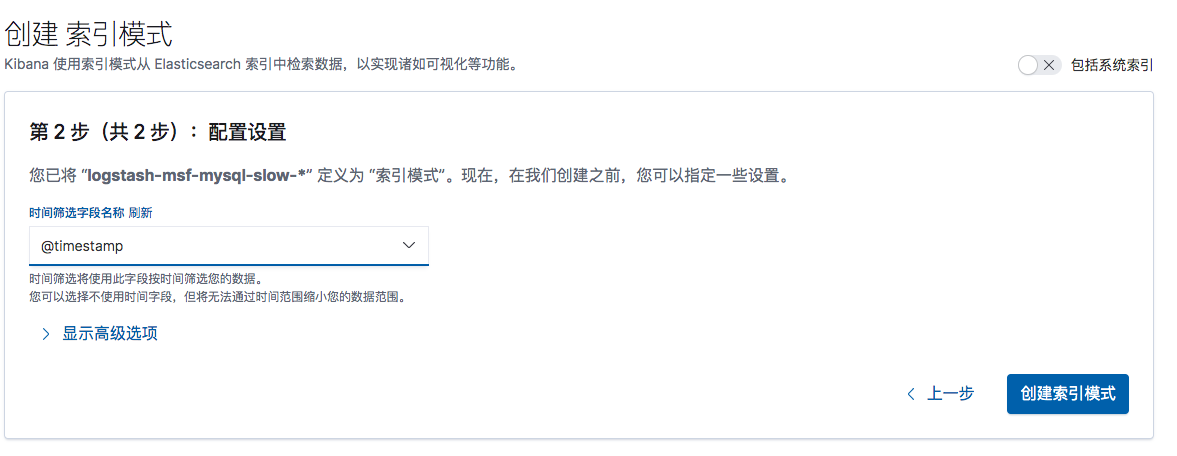
创建完成后,字段已经自动映射
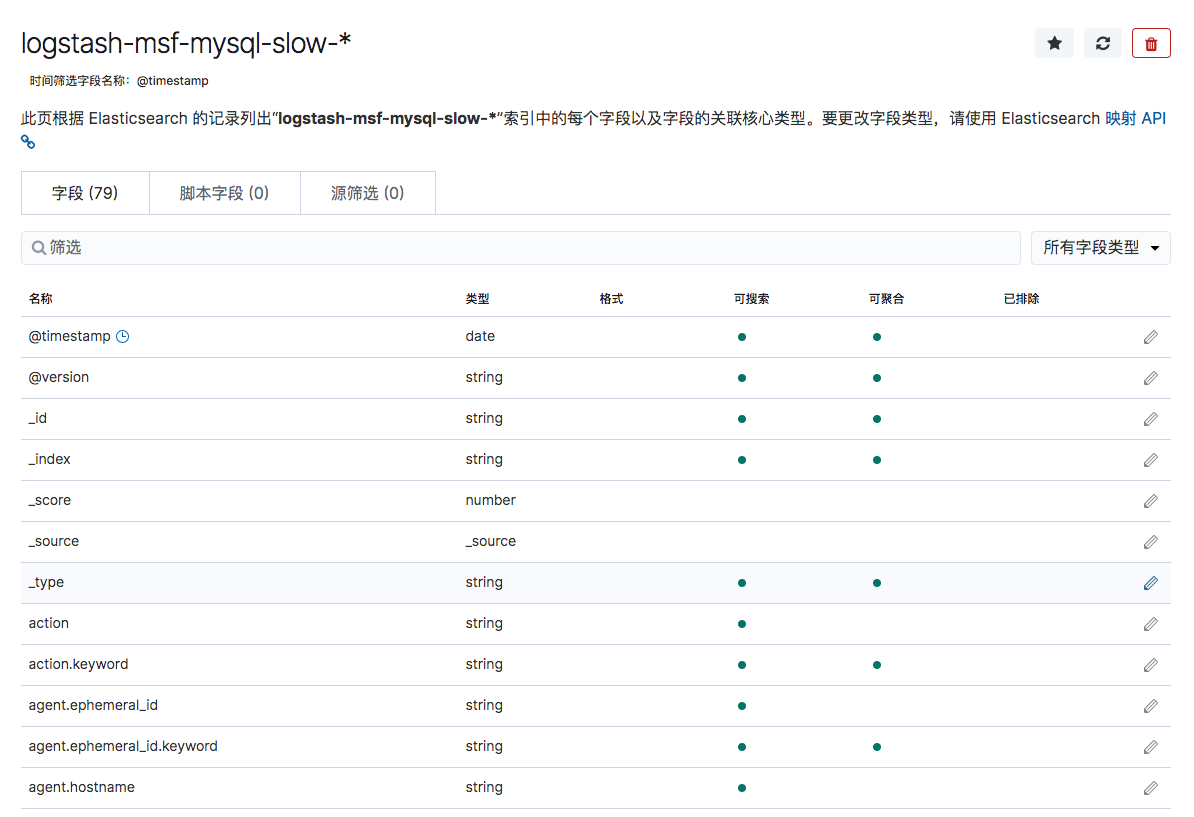
此时在discovery界面就能看到该索引并且该索引下的数据了.
索引生命周期
Kibana的管理界面可以管理索引的生命周期,在下面的图示中,创建一个新的生命周期策略
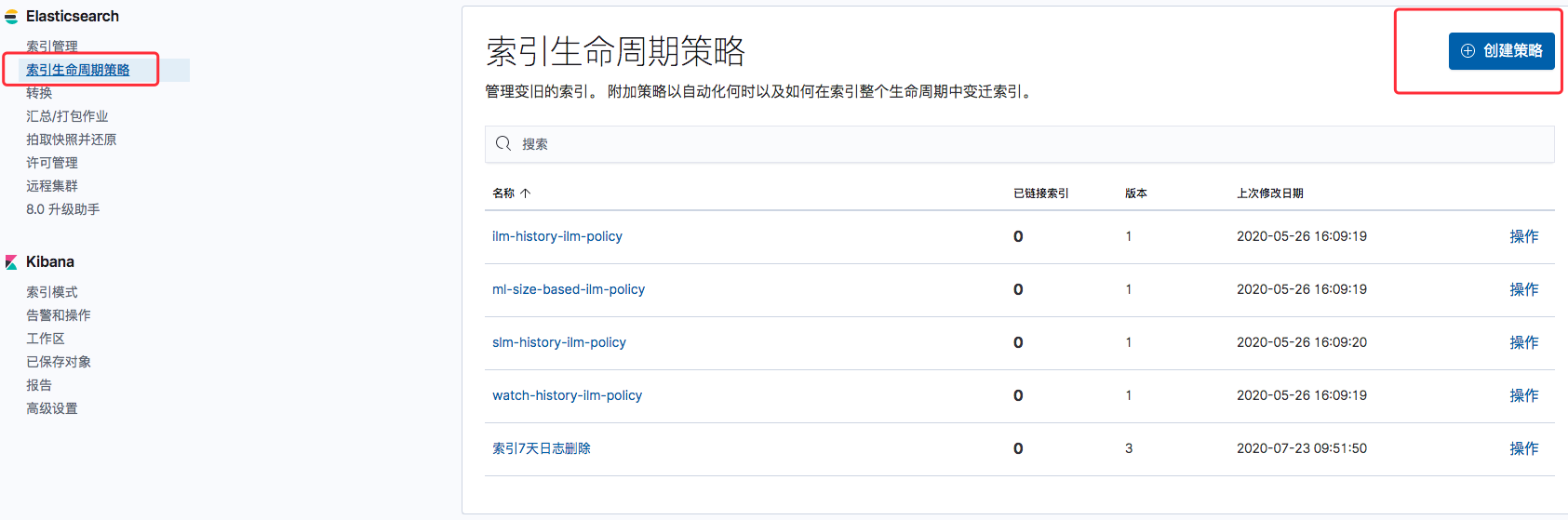
可以管理索引的生命周期,例如,下面的截图中配置超过2天的索引自动删除
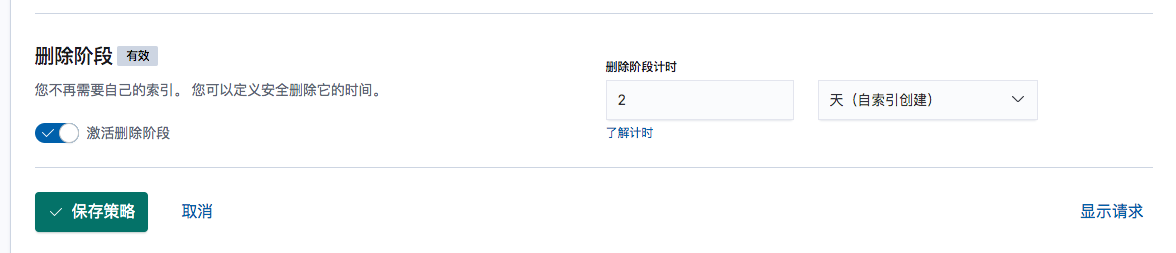
保存策略,然后将该策略关联到索引模板.
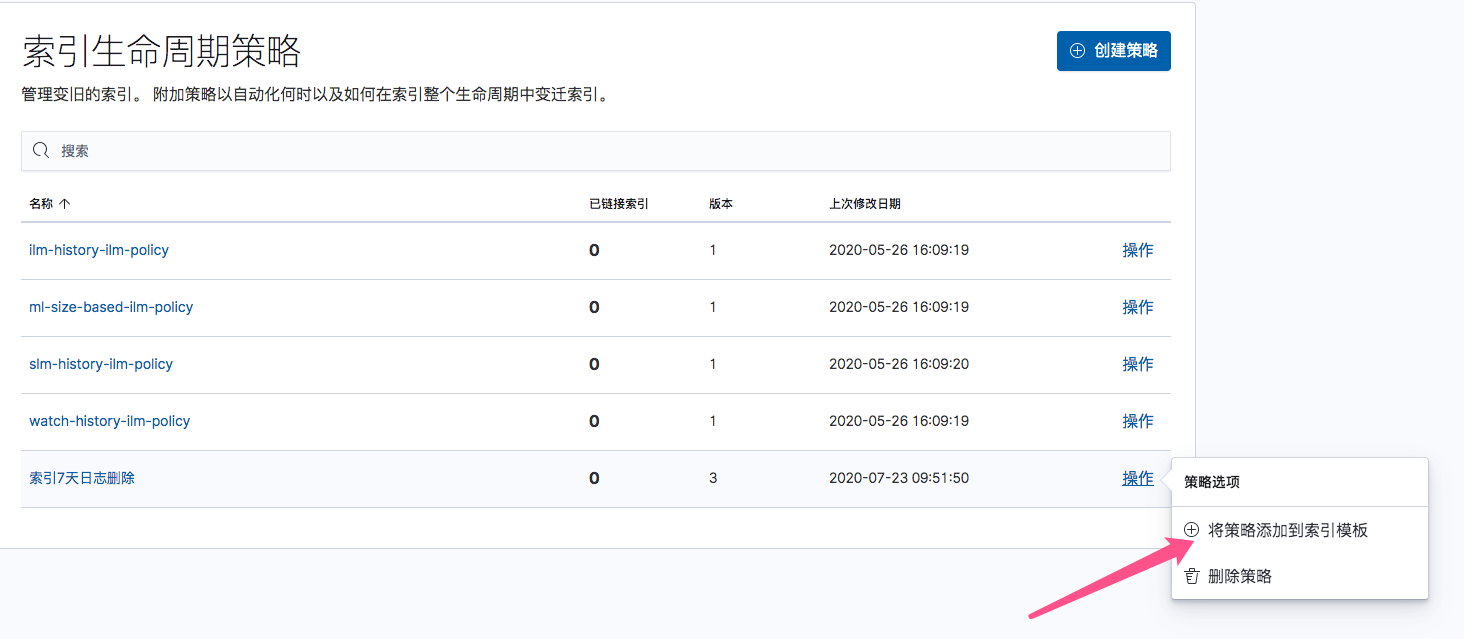
索引冷热分离管理
在<生产环境部署ELK+冷热数据分离>笔记中提到,当前业务每天大概1.5T左右的日志,规划了20T的SSD磁盘,刚好可以保留7天的日志(副本数为1).开发人员需要将日志保留更久(例如一个月),以便有些故障未能及时发现,可能数周后才去追踪日志,排查故障.
但是,将一个月的日志都存储在SSD的磁盘中成本较高.在这种场景中,可以使用冷热分离,将索引数据分开..例如,7天内的日志为热数据,该日志查询频率非常高,可以作为热数据,存储在ES的热节点,.7天后的日志查询频率就非常低,几乎很少查询,此时可以做为冷数据,存储在ES的冷节点.
ES冷节点通常硬件资源较低,CPU和内存配置相对热节点较低,磁盘通常采用机械磁盘,一方面冷节点无需太高配置,另一方面节省服务器成本费用
在<生产环境部署ELK+冷热数据分离>笔记中的ES集群截图中,可以看到每个ES的data节点都有hot或者cold属性..该属性定义了ES的冷热节点角色
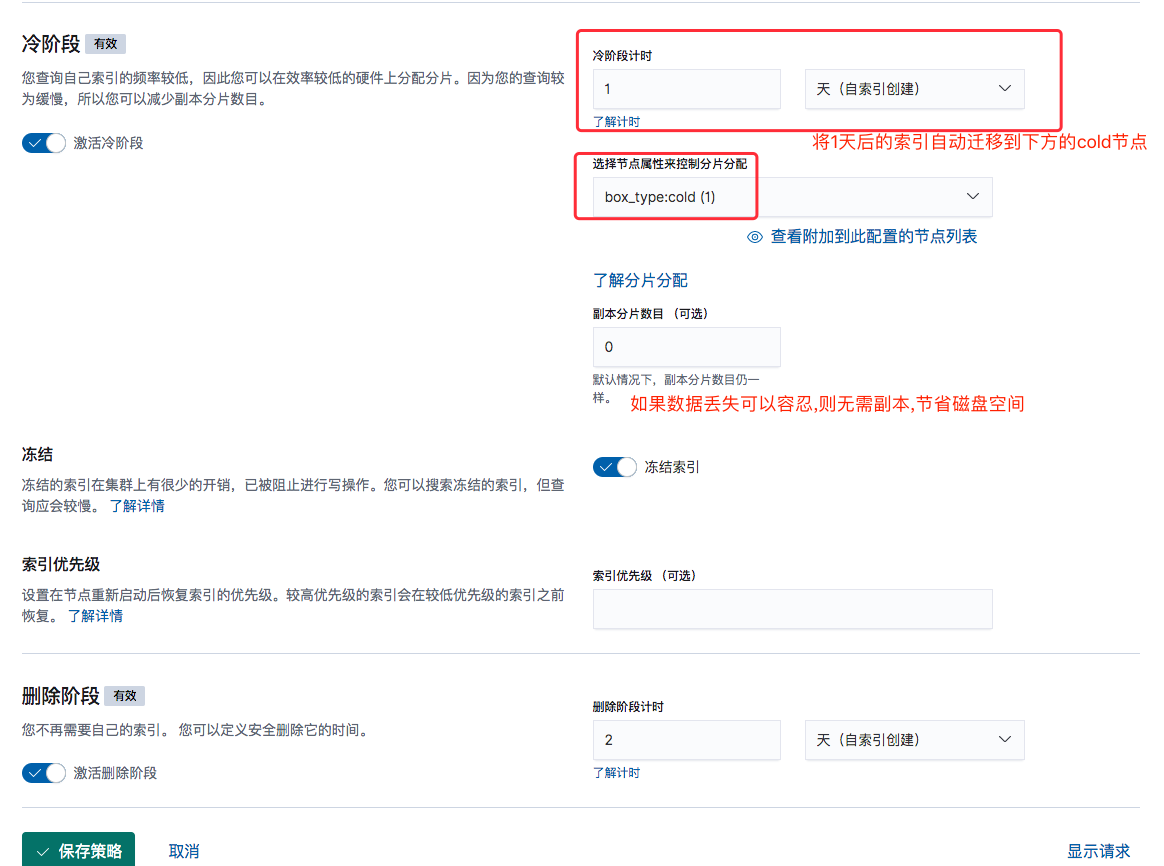
还是在上面的Kibana索引生命周期中配置冷热分离.只需开启冷阶段配置即可.配置参考如下:
接着在Kibana的dev tool工具中,给索引模板新增以下配置,将索引数据分配到hot节点ES服务器:
1 | PUT _template/logstash |
查看默认的logstash-*索引模板.可以看到设置已经生效
1 | "routing": { |
此后进来的索引数据,会自动存储到hot节点的ES服务器上.cold服务器不存储任何热数据
PS: 为了测试冷热数据是否正常工作,也可以手动将索引从Hot节点迁移到cold节点,以索引logstash-msf-fpm-error-2020.07.27为例,在Kibana的dev tool工具中执行下面的语句,
1 | PUT /logstash-msf-fpm-error-2020.07.27/_settings |
则该索引会增加下列属性:
1 | "routing": { - |
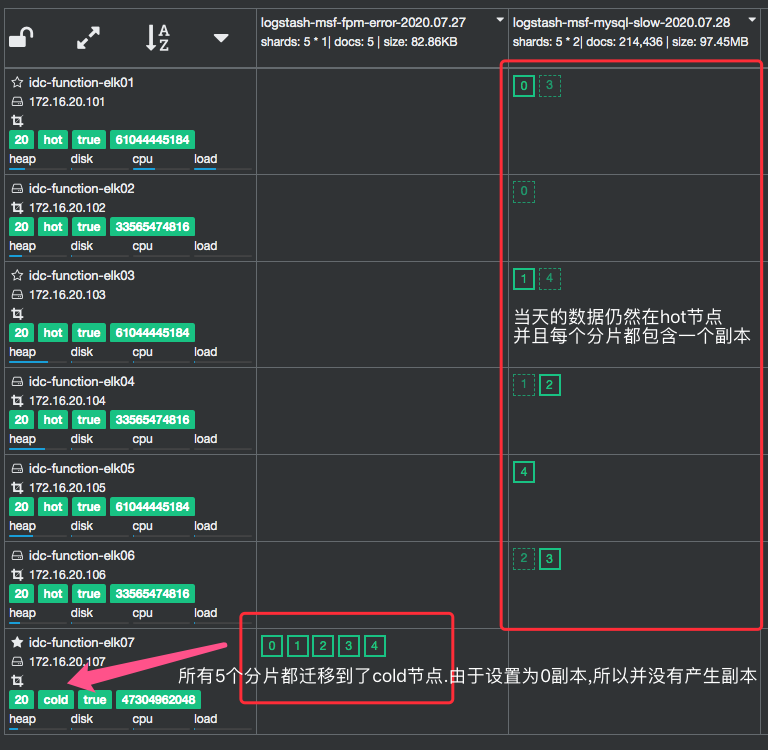
Kibana7版本的索引生命周期会自动迁移旧的索引数据到cold节点,所以无需手动或者写脚本定时迁移
Kibana的索引生命周期生效后,旧的索引就会自动从hot节点迁移到cold节点:
当配置了Kibana的索引生命周期后,logstash数据传输到ES时,只需要指定ES的Hot节点(或者master)节点即可,,cold节点(如果不是master)则无需写入到output配置中
索引模板配置
总结下来,索引模板需要做如下配置:
1 | PUT _template/logstash |
索引设置效果如下:
1 | { |
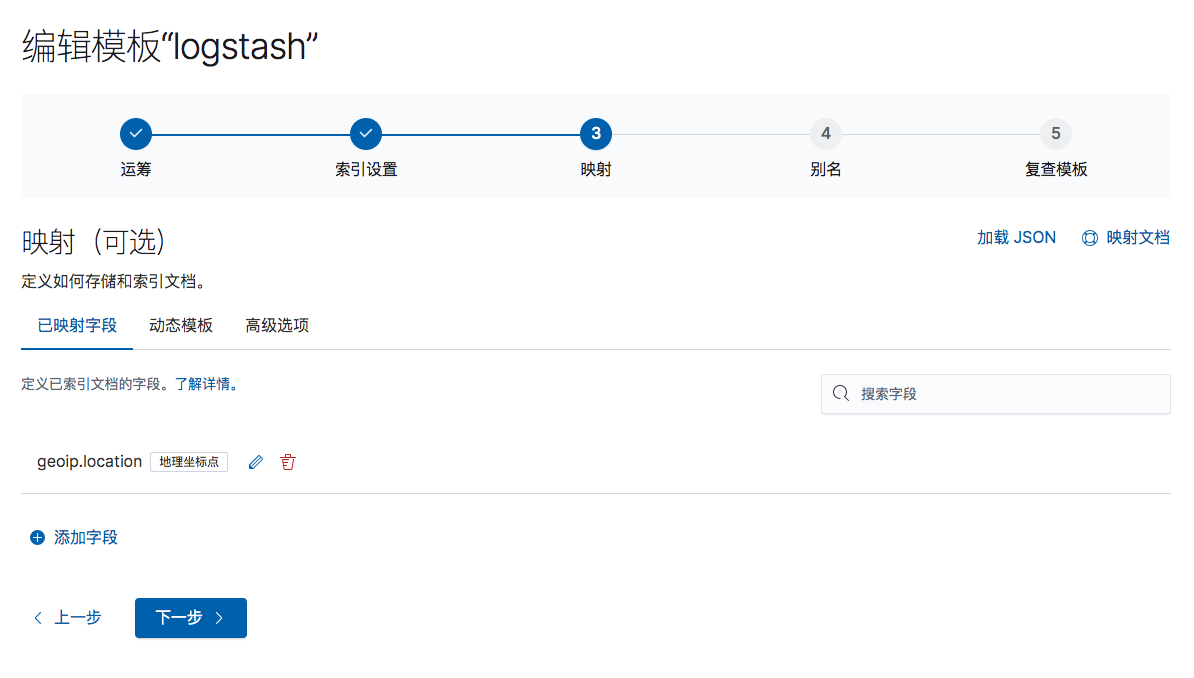
另外,有时候索引找不到geoip.location字段.此时就需要在索引模板中手动映射字段
手动添加映射字段:
字段名: geoip.location
字段值: 地理坐标点