ELK收集mysql5.7慢日志
介绍
公司ELK平台计划收集生产业务的所有mysql慢日志.由于所有环境中均使用mysql5.7版本,所以其他mysql版本的慢日志格式不在讨论范围之内.
慢日志的grok正则匹配我折腾了很久,网上的大多文档中给出的logstash的grok正则其实并不能正确的解析到mysql慢日志的字段.
这个博客的grok正则经过实践可行.而且filebeat,logstash的filter配置也是参考这个博客配置的:博客地址
MySQL慢日志
慢日志格式如下:
1 | [work@msf-mysql-master log]$ sudo head slow_2019072103.log |
每个日志文件的格式为slow_日期.log .7天切割一次新的日志文件
每个日志的开头三行是不需要的内容,所以需要filebeat排除
每一条慢日志有以下几行组成:
1 | # Time: 2019-07-21T08:54:04.145255+08:00 |
第一行Time时间不需要,所以也需要filebeat排除.
从第二行开始匹配,有些慢日志可能没有use database;的语句.所以需要分别针对对待
filebeat配置
filebeat需要开启多行日志功能.并且排除特定的字段.除此之外,和其他的日志收集配置一样.下面是生产环境中filebeat的配置
1 | - type: log |
logstash配置
logstash需要使用正则匹配2种格式的慢日志.当一种grok匹配到了后,logstash就不会再接着往下匹配了,所以每条日志只会匹配一种grok规则
1 | if [fields][type] == "mysql" { |
也可以将2个match语句写入到一个grok中,但是我试过好像不行,有些慢日志并不能正常解析
实际上无论是grok debbuger在线工具还是Kibana的dev tool均提供了grok的在线调试工具,可以检测和调试grok的正则匹配.例如使用上述中的grok正则检测一下是否能正常匹配到前文提到的mysql原始日志数据.可以使用kibana的dev tool工具中的Grok Debugger工具来校验:
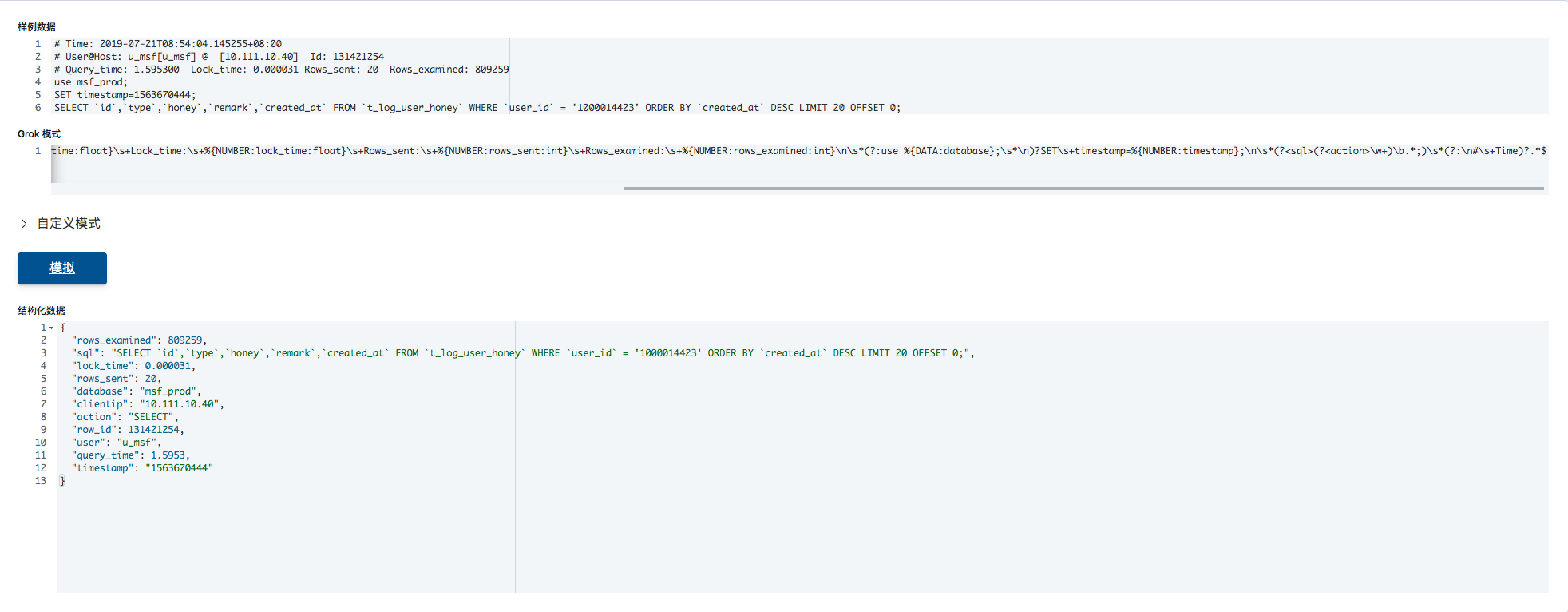
上面的结构化数据输出中可以看到grok正则能正常解析原始日志中的数据,并且以json格式将日志内容映射给各字段.
Kibana展示
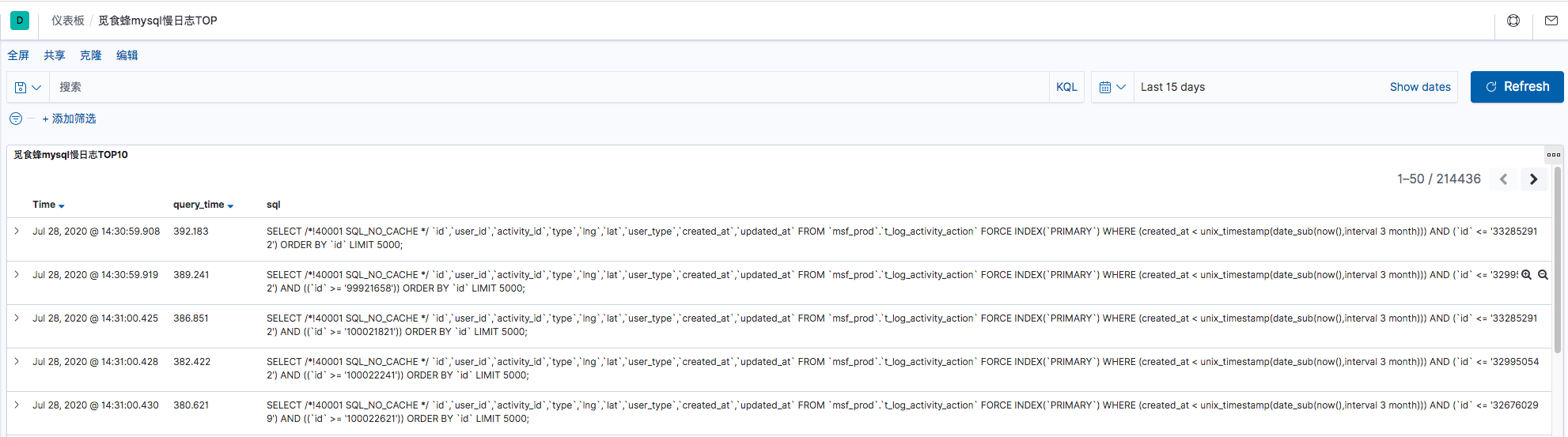
我尝试在kibana中使用图形化展示query_time(也就是SQL执行时间)最长的TOP5的SQL语句,制作成可视化图表,方便动态展示.但是发现可视化的聚合图形并不能满足这个需求.
但是Kibana的Discover界面通过选定字段,也能对query_time进行排序.例如下面的截图中先选定query_time和sql这2个字段,然后再对query_time进行排序(在右边的query_time字段下有个倒三角形表示倒序排序).
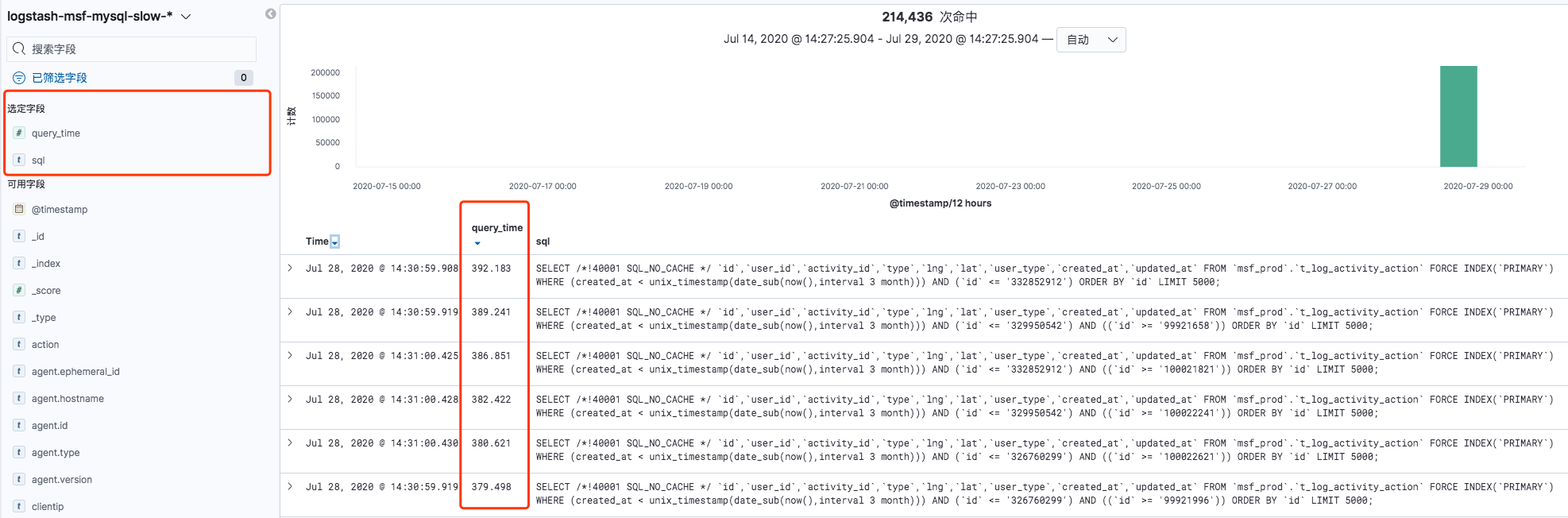
然后将这个discover的筛选结果保存到Dashboard中,方便以后查看: